
概述
计算机网络与互联网
计算机网络:指由若干节点(计算机、路由器、交换机、集线器等)和连接这些结点的链路组成的通信网络
因特网(Internet):又称互联网,指世界范围内基于TCP/IP协议族互联的计算机网络,它连接了全世界数十亿台计算设备,这些设备包括传统的PC、Linux工作站、路由器,以及智能手机、平板、家用电器、车机、工业系统等非传统设备。在因特网术语中,这些设备通常被称为主机(host)或端系统(endsystem)。
互联网的起源
互联网起源于20世纪60年代(1960年左右)美国国防部高级研究计划局(ARPA)主导的ARPANET(阿帕网)建设计划。该网络最初仅连接4个节点,其核心目标是在冷战背景下构建一种具备抗毁性的分布式通信系统。ARPANET首次在工程中验证了分组交换(Packet Switching)这一技术基础,为后续计算机网络体系结构奠定了理论与实践基础。
1983年,TCP/IP协议正式成为标准,解决了异构网络互联的核心难题,标志着真正意义上的“互联网”诞生。1989年,欧洲原子能机构的计算机科学家Tim Berners-Lee提出了万维网(WWW)的构想,并实现了包括HTML(超文本标记语言)、HTTP(超文本传输协议)以及浏览器在内的一整套技术体系,极大降低了互联网的使用门槛,为互联网的大众普及奠定了基础。90年代初,美国国家科学基金会(NSF)逐步取消了对互联网的商业使用限制,并于1995年将互联网主干网(NSFNET)彻底移交给私营的互联网服务提供商(ISP)负责运营。此后,互联网迅速走向大规模商业化与全球化普及,发展为如今连接全球数十亿设备的庞大网络。
互联网的标准化与协议
互联网协会(ISOC)是一个国际性非营利组织,负责从宏观上统筹互联网的发展方向、政策倡导与技术治理。其下属的互联网工程任务组(IETF)负责具体的互联网核心标准制定工作,并将成果以RFC(Request for Comments,RFC最初只是普通的请求评论,因此得名)文档形式公开发布,RFC定义了TCP、IP、HTTP、DNS等绝大多数关键的互联网协议。此外,IEEE等组织也会为互联网提供诸如802.3以太网标准、无线WIFI标准等网络传输标准,它们共同组成了互联网的基石。
RFC的关键作用之一就是描述协议,关于协议的定义:
- 《计算机网络自顶向下方法》:互联网协议(protocol)定义了在两个或多个通信实体之间交换的报文的格式和顺序,以及报文的发送/接收或其他事件所采取的操作。
- 《计算机网络》谢希仁书:网络协议(network proctocol,简称协议)指为网络中的数据交换而建立的规则、标准或约定,它由三要素组成:语法(数据与控制信息的结构或格式)、语义(要发出何种控制信息,完成何种动作以及做出何种响应)、同步(事件实现顺序的说明)
互联网的组成
互联网的拓扑结构非常复杂,从工作方式上看,互联网分为互联网边缘和互联网核心
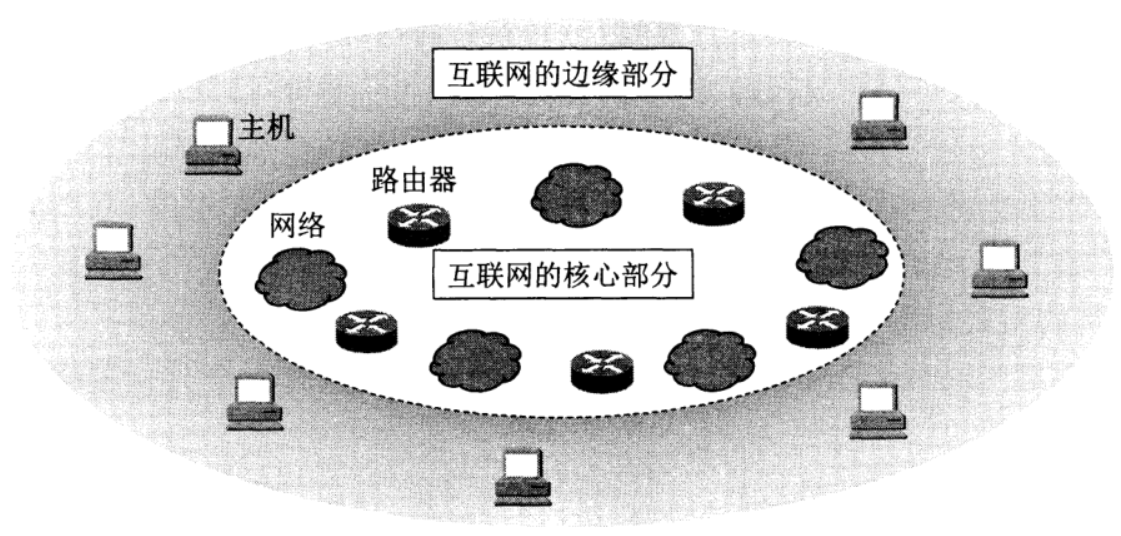
互联网的边缘
互联网边缘的部分包含所有连接在互联网上的主机,由于它们位于互联网的末端,因此又称为端系统(endsystem),通常由用户直接使用,端系统之间主要通过以下两种方式通信:
- 客户-服务器(Client-Server)方式:互联网上最常用的工作方式,通信双方角色固定,通常由客户端发起请求,服务器响应并提供服务,常见的网页服务、邮件服务属于该工作方式
- P2P对等连接(Peer-to-Peer)方式:各节点地位对等,通信双方既可以充当客户端也可以充当服务器,每个节点既是服务的请求者,也是服务的提供者(如BitTorrent),常用于文件分发、区块链、实时通信等领域
接入网
接入网负责将端系统物理连接到边缘路由器,有以下几种接入方式:
- 数字用户线DSL(Digital Subscriler Line,DSL):即通过住宅电话线(铜线)接入,住宅电话线同时承载宽带数据和传统电话信号,并使用频分复用技术:0-4kHz用于普通双向电话信道,4kHz-50kHz用于中速上行信道,50kHz-1MHz用于高速下行信道。DSL调制解调器负责将数字信号转换为高频模拟信号(或反过来),家用环境下,由于下行所需带宽远大于上行,因此常用子类型为ADSL(Asymmetric Digital Subscriber Line,非对称数字用户线路)
- 电缆因特网接入(cable Intemet access):利用有线电视公司现有的有线电视基础设施,来实现电缆因特网接入。常使用同轴电缆作为传输介质,类似于DSL,电缆调制解调器负责数字信号与模拟信号之间的转换。
- 光纤到户FTTH(Fiber To The Home):利用光纤作为宽带接入方式,速率可达千兆以上。它用光猫(ONU)取代传统电话调制解调器,来实现光信号和电信号之间的转换,是目前公认速度最快、可靠性最高的家庭接入方案
- 广域无线接入:通过蜂窝网提供商运营的基站来发送和接收分组,包括3G、LTE 4G、5G
互联网的核心
互联网的核心部分由大量网络和连接这些网络的路由器组成,其根本任务是为网络边缘的主机提供端到端的连接。在这个核心中,路由器是关键构建单元,它们以分组交换的形式高速转发数据,实现跨网络的传输数据。
分组交换采用存储转发技术,通常把要发送的整块数据称为一个报文(message),报文内容可以是普通的数据,也可以是控制数据。在发送报文之前,源端系统通常会将较长的报文分割为较小的数据块,并在数据块之前加上一些由控制信息组成的首部(header),构成一个分组(packet,又称为包),链路上的路由器会根据首部信息,独立地选择传输路径,并将分组正确地交付至传输终点。
存储转发需要路由器开始向输出链路传输该分组的第一个比特之前,必须接收完整的分组。之所以这么设计,主要有以下原因:
- 差错检测:检查分组是否在传输过程中出现了差错,差错检验需要完整的分组,如果校验出错,则丢弃分组,以免浪费后续链路带宽。
- 分片处理:不同的链路有不同的传输带宽,当分组需要进入一个MTU更小的链路时,路由器必须拥有完整的分组以便进行切片,或者直接丢弃分组(不允许分片时)
- 拥塞控制与队列管理:当多条输入流同时涌向同一条输出链路时,输出队列可能被填满,存储转发机制让路由器可以先将分组完整存入缓冲区,然后根据队列管理算法(如尾丢弃、RED等)决定是排队等待、优先转发还是主动丢弃
- 链路协议适配:不同的物理网络使用不同的链路层协议(如以太网、Wi-Fi、4G/5G、PPP等),它们的帧格式、最大传输单元(MTU)各不相同。路由器需要完整接收一个分组后,重新封装成下一跳链路所要求的帧格式。
计算机网络
计算机网络分类
- 广域网 WAN(Wide Area Network):作用范围通常为几十到几千公里,其任务是通过长距离(如跨越不同的国家)运送主机所发送的数据,广域网有时也称为远程网
- 城域网 MAN(Metropolitan Area Network):作用范围一般是一个城市,跨越几十公里,目前很多城域网采用的是以太网技术
- 局域网 LAN(Local Area Network):范围较小,通常在1km以内,通常一个学校,一间办公室都可以拥有一个局域网,局域网主要使用以太网技术
- 个人区域网 PAN(Personal Area Network):指把个人使用的电子设备用无线技术连接起来的网络,作用范围大约在10 m左右,通常又称为无线个人区域网WPAN(Wireless PAN)
计算机网络性能参数
- 速率:数据的传送速率,单位为bit/s或bps(bit per second),bit前可以加上K、M、G、T、P、E、Z、Y等单位
- 带宽:通信上指某个信号或信道具有的频带宽度,在计算机网络中,带宽用来表示网络中某通道传送数据的能力,单位可以使用数率的单位bit/s
- 吞吐量(throughput):表示在单位时间内通过某个网络(或信道、接口)的实际的数据量,对于一个1Gbit/s的以太网,其吞吐量上限为1Gbit/s,但其实际的吞吐量可能只有100 Mbit/s。有时,吞吐量还可用每秒传送的字节数或帧数来表示
时延
时延(delay或latency,又称延迟)是指数据(一个报文/分组甚至比特)从链路的一端传送到另一端所需的时间,它由以下几个不同的部分组成的:
- 发送时延(transmission delay):指主机或路由器从发送数据帧的第一个比特算起,到该帧的最后一个比特发送完毕所需的时间,该时延发生在网卡中
- 传播时延(propagation delay):电磁波在信道中传播一定的距离需要花费的时间,该时延发生在传输链路的物理媒介上,电磁波在自由空间的传播速率为3x105km/s,在物理层传输介质中的传播速率比在自由空间要略低一些,如在铜线电缆中的传播速率约为2.3x105km/s,在光纤中的传播速率约为2.0x105km/s,因此1000 km长的光纤线路产生的传播时延大约为5ms。
- 处理时延:主机或路由器在收到分组时分析分组的首部、从分组中提取数据部分、进行差错检验或查找适当的路由等操作,产生的处理时延。
- 排队时延:分组在路由器的输入队列中排队等待处理,以及路由器确定了转发接口后,在输出队列中排队等待转发所产生的排队时延。当网络的通信量很大时会发生队列溢出,使分组丢失,这相当于排队时延为无穷大。
数据在网络中的总延时为以上四种延时之和:
时延带宽积
时延带宽积即链路的传播时延与带宽的乘积,它是衡量链路容纳能力的性能指标。可以简单将链路想象为一个水管,带宽是水管的粗细,传播时延是水管的长度,因此时延带宽积就代表这条水管的容积。如:假设某段链路的传播时延为20ms,带宽为10Mbit/s,则时延带宽积=20×10-3×10×106=2×105bit,这表示如果发送端持续发送数据,当发送的第一个比特到底即将终点时,链路上有20万个比特正在传输,因此时延带宽积又称为以比特为单位的链路长度。当发送的数据量超过时延带宽积,就意味着管道已被填满,此时继续发送会造成网络拥塞或数据丢失。因此,高效的传输协议往往需要让发送窗口的大小与时延带宽积相匹配。
往返时间RTT
往返时间RTT(Round-Trip Time):指一个数据包从发送端发出开始,到发送端接收到来自接收端的确认信号为止,所经历的总时间。
利用率
利用率分为
- 信道利用率:指出某信道有百分之几的时间是被利用的(有数据通过),完全空闲的信道的利用率是零
- 网络利用率:全网络的信道利用率的加权平均值。信道利用率并非越高越好,当某信道的利用率增大时,该信道引起的时延也就迅速增加(因为分组在路由器/交换机等网络结点要派对等待处理)。如果令D0表示网络空闲时的时延,D表示网络当前的时延,则它们与利用率U之间的关系为: D=D0/(1-U)
计算机网络体系结构
最初的ARPANET在设计之初就提出了网络分层的思想,“分层”可将庞大复杂的网络问题拆分为若干较小的局部问题,便于研究和处理。1974年,IBM发布了按分层方法制定的系统网络体系结构 SNA(System Network Architecture),至今仍在IBM大型机构建的专用网络中沿用。此后,多家公司也相继推出各自的专有体系结构。为统一标准,国际标准化组织(ISO)提出了著名的开放系统互连基本参考模型OSI/RM(Open Systems Interconnection Reference Model),简称OSI,旨在为全球计算机互连提供一套标准框架。
OSI试图达到一种理想境界,即全球计算机网络都遵循这个统一标准,并在20世纪80年代得到了许多大公司甚至部分政府机构的支持。然而,到20世纪90年代初期,基于TCP/IP的互联网已抢先在全球大范围成功运行,同时市面上却几乎找不到符合OSI标准的商用产品,TCP/IP由此成为事实上的国际标准。
五层协议体系结构
OSI七层模型把对等层次之间传送的数据单位称为协议数据单元PDU(Protocol Data Unit),其协议体系结构理论清晰,但协议复杂且不实用。TCP/IP四层的体系结构使用广泛,但结构过于简略,因此很多书籍在描述计算机网络的原理时往往采取折中的办法,综合OSI和TCP/IP的优点,采用一种只有五层协议的体系结构。
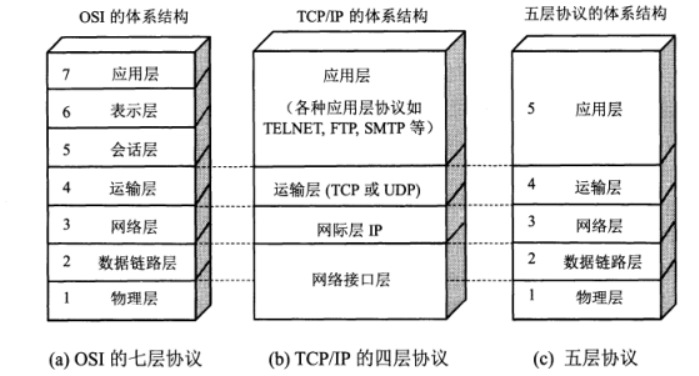
在五层体系结构中,网络通信被划分为应用层、运输层、网络层、数据链路层和物理层,它们传输的数据单元,都可笼统地用分组表示,各层分工明确、逐层协作:
- 应用层直接面向用户应用,负责提供网络服务与数据交换,其传输的数据单元称为报文(Message),常见协议包括HTTP、DNS、FTP、SMTP等
- 运输层负责端到端的数据传输、可靠性控制以及端口复用,运输层传输的数据单元可以统称为报文段(segment),主要使用以下两种协议:
- 传输控制协议TCP(Transmission Control Protocol)提供面向连接的、可靠的数据传输服务,其传输的数据单元称为报文段(segment)
- 用户数据报协议UDP(User Datagram Protocol)提供无连接的、尽最大努力的数据传输服务,不保证数据传输的可靠性,传输的数据单元称为用户数据报(segment)
- 网络层又称网际层或IP层,负责逻辑寻址与跨网络路由选择,使数据能够从源主机到达目标主机,其传输的数据单元称为数据报(Datagram)或分组(Packet),核心协议包括 IP、ICMP、OSPF 等
- 数据链路层简称链路层,负责相邻节点之间的数据传输、差错检测以及帧封装,传输的数据单元称为帧(Frame),常见协议包括以太网、PPP、802.11 Wi-Fi等
- 物理层负责在传输介质上发送和接收比特流,定义电气特性、接口标准和传输方式,传输的数据单元是比特(Bit),针对同轴电缆、双绞线、光纤等不同传输介质,使用不同物理传输标准
TCP/IP体系
互联网所使用的诸多协议中,最知名的是TCP和IP协议,因此人们习惯使用TCP/IP协议族(protocol suite)泛指互联网所使用的整个协议体系,由于其层次结构很像栈结构,因此又使用协议栈(protocol stack)来表示TCP/IP族中的一系列协议。
随着技术的发展,实际上现在的互联网使用的TCP/IP体系结构有时已经演变成为下图所示,即某些应用程序可以直接使用IP层,或甚至直接使用最下面的网络接口层
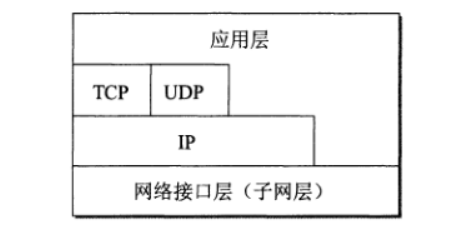
应用层
URI统一资源标识符
统一资源标识符URI(Uniform Resource Identifier)用于唯一标识某个资源,它只强调“标识”,URL和URN都是URI的子集。
URN统一资源命名符
统一资源命名符URN(Uniform Resource Name)用来唯一、永久地标识资源名称,不包含访问方式或具体位置,它只强调资源的永久名称,资源在移动位置后URN不变(但URL通常会发生改变),常用于永久标识一本书、一份文档、一个UUID、或在XML文件中命名空间防止标签冲突等,典型格式为:
URL统一资源定位符
统一资源定位符URL(Uniform Resource Locator)用于在标识资源的位置和访问资源的方式,它不仅标识资源,还说明获取方式和位置,强调“定位”,典型格式为:
- 协议:协议后紧跟:号,常用协议有:
- 网络协议:http、https、ws、wss
- 文件传输协议:ftp、sftp、ftps
- ssh协议:ssh://root@example.com:22
- 电子邮件协议mailto:mailto:njsgcn@gmail.com?subject=标题&body=内容
- 电话tel:tel:+86xxxxxx
- 短信sms:sms:+86xxxx?body=内容
- 本地文件file:file:///C:/Users/name/Documents/file.pdf
- 本地数据data:data:[<MIME类型>][;charset=<字符集>][;base64],<编码数据>,如data:image/png;base64,iVBORw0KGgo
- 大型本地内存对象blob:blob:http://xxx.com/xxx
- js代码:javascript:alert(‘Hello’)
- 地理位置geo:定位北京坐标并缩放4倍geo:39.9042,116.4074?z=4
- 资源命名符urn
- 用户信息:以username[:password]@标识用户名和密码,但现代 Web很少在URL里明文传密码
- 主机名:可以是域名(www.example.com)、IPv4地址(192.168.1.1)、IPv6地址必须用方括号包裹([2001:db8::1])、本地回环地址localhost,部分协议mailto、tel等不需要主机名
- 端口:以:数字形式添加,如果使用协议对应的默认端口,则可以省略
- 路径:通过/分隔标识资源路径,可以为空(表示隐藏的根路径/)
- 查询参数:以?开头,键=值形式添加,多个参数使用&分隔
- 片段:以#开头,用于定位页面内某个锚点或元素ID,它不会被发送给服务器,只在客户端使用
应用层协议概述
应用层协议(application-layer protocol)定义了运行在不同端系统上的应用程序进程如何相互传递报文,它们大多数都是以客户-服务器方式工作,协议主要包括以下内容:
- 交换的报文类型,例如请求报文和响应报文。
- 各种报文类型的语法,如报文中的各个字段及这些字段是如何描述的。
- 字段的语义,即这些字段中信息的含义。
- 确定一个进程何时以及如何发送报文,对报文进行响应的规则。
超文本传输协议HTTP
HTTP概述
超文本传输协议HTTP(HyperText Transfer Protocol)定义了用户代理(user agent,通常是Web浏览器,也可以是爬虫等各类程序)如何向Web服务器请求Web文档(可以是html、图片等各类资源),以及服务器如何向客户回送这些文档。它是一种面向事务的应用层协议,使用TCP作为运输协议,默认使用80端口。
服务器为客户提供http服务时,服务器不存储任何关于该客户的状态信息,假如某个客户在短短的几秒内两次请求同一个对象,服务器也不会记得刚刚为该客户提供过服务,就像服务器已经完全忘记不久之前所做过的事一样。因此,HTTP是一个无状态协议(stateless protocol)
HTTP的工作流程
往返时间(Round-Trip Time,RTT):指一个短分组从客户到服务器然后再返回客户所花费的时间。RTT包括分组传播时延、分组在中间路由器和交换机上的排队时延以及分组处理时延
HTTP客户端在发起TCP连接时,三次握手中前两部分占用一个RTT,第三次握手和服务器响应占用另一个RTT,总响应时间为两个RTT加服务器传输HTML文件的时间。
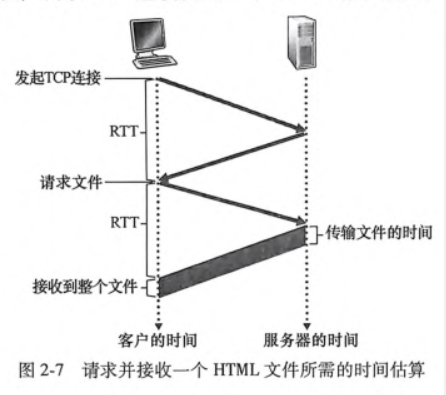
HTTP/1.0
HTTP的最初的版本是HTTP/1.0,诞生于20世纪90年代初,它采用非持续连接(non-persistentconnection),即每次请求都需要单独建立一次TCP连接,响应完成后会立即断开。这意味着如果一个页面包含大量链接对象(如图片、css、js资源),客户端需要反复创建连接,每一个链接都会带来至少2*RTT+的开销。对于服务器端,它可能需要同时处理数百个不同客户端的请求,为非持续连接分配TCP缓冲区和维护TCP变量,都会带来极大的负担。
HTTP/1.1
HTTP/1.1协议引入了长连接(Keep-Alive)机制,很好地解决了上述问题,它通过维持一个持续连接(persistent connection,可以通过Connection标头控制),允许所有的请求及其响应通过同一个TCP连接传输。HTTP 服务器和客户端在发送响应后,可以在一段时间内继续保持该连接,以便后续的HTTP请求和响应报文可以在同一条连接上继续传输。这种复用不限于同一页面内的文档,同一服务器上的其他文档也可共享该连接。到2020年为止,绝大部分的HTTP事务都采用HTTP/1.1协议。
HTTP/1.1协议的持续连接有两种工作方式:
- 非流水线方式:客户端在收到前一个响应后才能再发出下一个请求,因此获取客户端每获取一个对象都要用去一个RTT时间,服务器在发送完一个对象后,TCP连接处于空闲状态,因此该方式会浪费服务器资源。
- 流水线方式:客户不需要等待前一个响应,在收到上一个响应之前就能发送新的请求,服务器也能连续发回响应报文,客户端访问所有对象只需要花费一个RTT时间。
客户端在流水线工作方式下连续发送多个请求时,HTTP/1.1服务器必须严格按请求顺序依次发回响应,这会带来队首阻塞(Head Of Line blocking,简称 HOL)问题。如:客户端连续发了请求A、B、C,由于这些请求没有序号(http2引入了序号机制),因此服务器(在同一个TCP连接上)必须严格按顺序返回响应A,响应B和响应C。如果生成响应A需要花费很多时间(如查询数据库,生成报告等),那么它会阻塞后续所有响应,即便服务器已经先准备好了响应B和响应C,也不能先行发回。(假设发送过程中,请求A在路由时绕路了,请求B先到达服务器,由于TCP会按序交付数据,所以请求依旧会被按序交付)。
因此即便http1.1有流水线机制,很多浏览器还是更愿意打开多个并行的TCP连接来避免HOL阻塞。
HTTP/2
HTTP/2针对HTTP/1.1的并发瓶颈进行了大量优化。HTTP/1.1虽然支持长连接,但带来了HOL阻塞问题,为解决这一问题,HTTP/2不再沿用HTTP/1.1中“请求行 + 文本头部 + 消息体”的纯文本报文格式,而是采用二进制分帧机制(Binary Framing)。
在HTTP/2中,每一次HTTP请求都会被抽象为一个Stream(流),并分配唯一的Stream ID。浏览器会将请求与响应拆分为多个可独立传输的二进制Frame(帧),例如用于传输请求头的HEADERS Frame,以及用于传输消息体的DATA Frame。所有Frame都可以在同一个TCP连接中传输,并允许来自不同Stream的Frame交错发送与接收,如:A1 B1 C1 A2 B2 C2,而不再需要像HTTP/1.1那样:A1A2A3 B1B2 C1C2C3C4,该机制使多个请求与响应能够真正并发传输,从而解决了HTTP层的队头阻塞问题
此外,HTTP/2还引入了HPACK头部压缩机制,通过静态表、动态表以及字段复用来减少重复头字段的传输开销;同时支持服务器推送(Server Push),服务器可在客户端尚未明确请求资源时主动发送相关资源,从而进一步降低页面加载延迟。
不过HTTP/2底层仍然基于TCP协议,因此TCP的按序交付的特性依旧存在。当某个TCP数据段丢失时,即便后续数据已经到达,TCP也必须等待丢失部分完成重传后,才能继续向上层交付数据。这会导致同一连接上的所有HTTP Stream一起被阻塞,即TCP层的队头阻塞。因此HTTP/2虽然解决了HTTP层HOL问题,但并未解决TCP层HOL问题。
HTTP/3
HTTP/3进一步将底层传输协议从TCP改为基于UDP实现的QUIC协议。QUIC在用户态实现可靠传输、流量控制与加密,并为不同数据流提供独立的重传机制,使某个流发生丢包时不会阻塞其他流,从而解决了TCP层的队头阻塞问题。同时QUIC将TLS握手与传输过程整合,大幅减少连接建立时延,使HTTP/3在高延迟、弱网和移动网络环境下具有更好的性能表现。
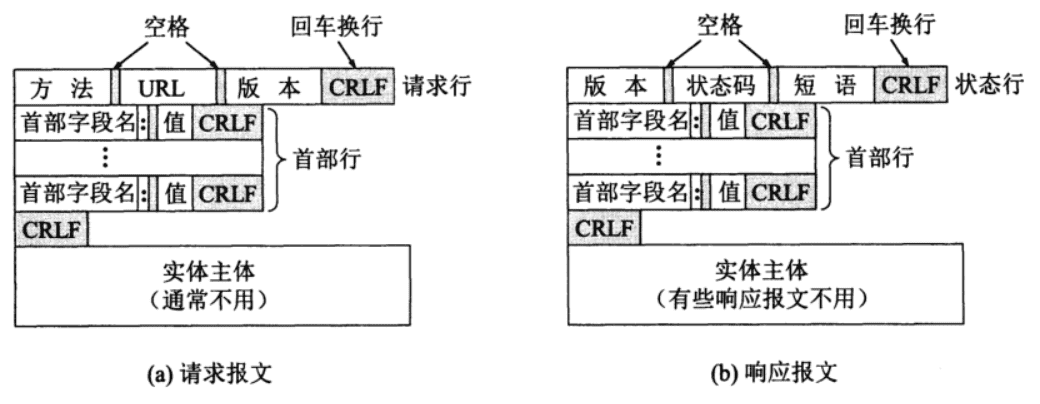
HTTP的报文结构
HTTP报文分为请求报文和响应报文,报文都由三部分组成:请求行/状态行、首部行、消息体(旧文档称为实体主体entity body,现代文档称为有效载荷主体payload body):
- 请求行/状态行、首部行所有字段都必须使用ASCII字符集(这意味着不允许使用中文)
- 每行都由一个回车”CR”和换行”LF”结束
- 消息体可以是任意二进制数据
- 首部行与消息体之间有一个空行
请求报文
请求报文示例(在本例中,浏览器实现的是 HTTP/1.1版本)
请求行
请求报文的第一行称为请求行(request line),由方法、请求URL、HTTP版本三个字段组成,以下是HTTP支持的方法:
| 方法 | 请求体 | 说明 |
|---|---|---|
| GET | 通常不用 | 请求URL所标识的资源,不应在请求体中发送数据(但有些实现支持),幂等且安全,常用于获取资源 |
| POST | 存放提交的数据 | 向服务器提交数据,请求体中存放需要提交的数据,非冥等,常用于表单提交、文件上传、API创建操作 |
| PUT | 存放上传的资源 | 在指定的URL下存储一个文档,冥等,常用于整体替换目标资源,请求体包含资源的完整新表示 |
| PATCH | 存放修改的内容 | 修改指定URL中的部分内容,不保证幂等(取决于实现),用于对资源进行部分修改 |
| DELETE | 通常不用 | 删除URL所标识的资源,冥等,常用于移除资源 |
| HEAD | 通常不用 | 请求URL所标识资源的首部,只返回响应头,不返回消息体,安全且幂等,常用于调试跟踪、探测资源是否存在等 |
| OPTION | 通常不用 | 查询服务器或资源所支持的通信选项,返回允许的方法、头部等信息,不直接操作资源本身 |
| TRACE | 通常不用 | 服务器会原样返回收到的请求,用来进行环回测试,诊断请求在中间节点的传输路径 |
| CONNECT | 通常不用 | 客户端请求代理与目标服务器建立TCP隧道,常用于建立隧道连接,最典型用途是HTTPS代理 |
首部行
首部行每一行都表示一个HTTP标头,为服务器提供关于所需数据的信息(如语言,或 MIME 类型),或是一些改变请求行为的数据(例如当数据已经被缓存,就不再应答),最后,首部行后会添加一个空行以分隔标头和请求体。标头遵循以下规则:
- 不区分大小写
- 以标头名:值形式填写
- 伪标头通常以:作为前缀
- 自定义标头通常以X-作为前缀
请求体
请求体通常用来在POST、PUT、PATCH方法下存放需要传输数据,其他方法下通常为空(但某些特殊实现依旧可能带有请求体)
响应报文
状态行
响应报文的第一行称为状态行,包括HTTP协议版本、状态码、人类可读的状态描述,常用的HTTP状态码和状态描述:
- 1xx信息响应:
- 100 Continue:这是一个临时响应,用于向客户端表明当前内容均可行,客户端应继续其请求
- 101 Switching Protocols:用于响应客户端请求切换协议时的Upgrade请求头,表示服务器同意协议,并指明服务器即将切换的协议
- 102 Processing:表示服务器已收到并正在处理该请求,但当前暂时没有响应可用
- 103 Early Hints:与Link链接头一起使用,以允许用户代理在服务器准备响应阶段时开始预加载 preloading 资源
- 2xx成功响应:
- 200 OK:请求成功,不同的请求方法会返回不同的响应体:GET(响应体中是请求的资源),HEAD(响应体中是所请求资源的首部),PUT/POST(所执行的结果),TRACE(响应体中是服务器所收到的请求)
- 201 Created:已创建新资源。这通常用于响应POST/PUT请求
- 202 Accepted:请求已经接收到,但尚未处理
- 203 Non-Authoritative Information:返回的信息来自副本
- 204 No Content:请求成功,但没有内容可发送,无响应体
- 205 Reset Content:请求成功,客户端应重置文档
- 206 Partial Content:返回部分内容(Range 请求)
- 3xx重定向:
- 300 Multiple Choices:请求拥有多个可能的响应,用户代理或者用户应当从中选择一个
- 301 Moved Permanently:资源永久移动,请求资源的URL已永久更改,在响应中给出了新的 URL
- 302 Found:资源临时移动,所请求资源的URL已暂时更改,浏览器会自动向新的URL发起请求
- 303 See Other:指示客户端通过GET方法访问新地址,以获得请求的资源
- 304 Not Modified:所请求的资源未修改(缓存命中),客户端可以继续使用相同的缓存版本
- 307 Temporary Redirect:类似302,资源临时重定向,浏览器在对新URL发起请求时,必须使用与上一个URL相同的请求方法
- 308 Permanent Redirect:类似于301,资源永久重定向,同样,对新URL的请求必须保持与上一URL请求相同的方法
- 4xx 客户端错误:
- 400 Bad Request:错误请求,服务器无法理解请求
- 401 Unauthorized:未授权,需要身份验证
- 403 Forbidden:禁止访问,服务器拒绝执行
- 404 Not Found:未找到,资源不存在
- 405 Method Not Allowed:方法不允许,请求方法不支持(如对只读接口用POST)
- 408 Request Timeout:请求超时,服务器等待请求时超时
- 409 Conflict:冲突,请求与当前资源状态冲突(如版本冲突)
- 413 Payload Too Large:载荷过大,上传的文件太大
- 415 Unsupported Media Type:不支持的媒体类型,Content-Type不被支持
- 429 Too Many Requests:请求过多,超出限流策略
- 5xx服务器错误:
- 500 Internal Server Error:服务器内部错误
- 501 Not Implemented:未实现,服务器不支持请求的功能
- 502 Bad Gateway:错误的网关,上游服务器返回无效响应
- 503 Service Unavailable:服务不可用,服务器过载或维护中
- 504 Gateway Timeout:网关超时,上游服务器超时
首部行
与请求报文的首部行类似,每一行都表示一个HTTP标头,为客户端提供关于所发送数据的一些信息(如类型、数据大小、使用的压缩算法、缓存指示),并以空行结束。
响应体
存放服务器响应的内容,如:HTML文档、JSON、图片、各类文档等,部分响应报文的响应体也可能为空
Cookie
HTTP Cookie是服务器发送到用户浏览器并保存在本地的一小块数据,用于告知服务端两个请求是否来自同一浏览器,以实现对无状态的HTTP协议的功能扩展,如:保持用户登录状态、跟踪分析用户行为等,Cookie通过以下流程工作:
- 客户端发起HTTP请求
- 服务器收到HTTP请求后,创建一个或多个Cookie,并在响应标头里添加对应的Set-Cookie
- 客户端收到响应后保存Cookie
- 客户端之后再访问该服务器,会从Cookie文件中取出该网站对应的Cookie,并添加到HTTP Cookie标头中,方便服务器识别
[页面内容] 2. 客户端再次发起的请求中,包含Cookie GET /sample_page.html HTTP/1.1 Host: www.example.org Cookie: yummy_cookie=choco; tasty_cookie=strawberry
DNS域名系统
域名系统DNS(Domain Name System):是一种将人类可读的主机名(域名)转换为机器可用的IP地址的分布式目录服务,DNS协议通常运行在UDP之上,使用53号端口。
域名结构
域名由多层次的标号组成,各标号之间用
- 由英文、数字、连字符-组成,不允许使用其他字符
- 不区分大小写
- 每一个标号不超过63个字符,多个标号组成完整域名不超过255个字符在大多数情况下,根域会被忽略不显示,如: www.example.com. 根域的域名是空白,因此通常末尾只有.号 顶级域名为com 二级域名为example 三级域名为www
DNS服务器
DNS服务器使用分布式、层次设计,它们分为以下类型:
- 根域名服务器:最高层次的域名服务器,负责提供TLD服务器的IP地址。目前世界上有数千台根DNS服务器,这些根服务器是13个不同根服务器的副本(13个根服务器域名为从a-m为前缀的a.rootservers.net…m.rootservers.net)。根域名服务器使用了任播技术以加快DNS查询,任播IP数据报的终点是一组在不同地点的主机,但它们具有相同的IP地址,IP数据报交付离源点最近的主机。
- 顶级域名服务器(TLD):负责管理在该顶级域名服务器下注册的二级域名。常见的顶级域名有:com(公司),net(网络服务机构),org(非营利组织),edu(教育部门),gov(政府部门),以及表示国家的cn(中国),us(美国)等。顶级域名服务器在国内由中国互联网络信息中心 CNNIC 运营管理。
- 权威域名服务器:客户端所查询域名的IP地址最终来源,顶级域名服务器通常不直接提供二级域名的IP地址,而是会告诉本地DNS服务器其权威域名服务器的地址,再由本地DNS服务器向权威域名服务器进行迭代查询,因此权威域名服务器才是所查询域名的IP地址来源。权威域名服务器通常由域名托管服务商(如:GoDaddy、Cloudflare、阿里云)以及大型企业(Google、AWS、腾讯)、大学/银行(可能自己架构,也可能托管于专业的互联网公司)负责维护架构。
- 本地域名服务器:又称默认域名服务器,它不属于域名服务器的层次结构,但它是进行DNS查询的主力。在windows中,可以通过设置-网络和Internet-WLAN/以太网-当前网络的属性-Internet协议版本4-属性中,就可以看见当前使用的本地域名服务器。它通常由ISP提供,或者可以使用Google(8.8.8.8),Cloudflare(1.1.1.1)的公共DNS作为我们的本地域名服务器。
域名解析的流程
- 主机向本地域名服务器的递归查询:当主机向本地域名服务器进行DNS查询时,如果本地域名服务器不知道所查询域名的IP,它会以DNS客户身份向其他根域名服务器/权威域名服务器发出查询请求,而不是让主机进行下一步查询。因此,本地域名服务器是DNS查询中工作最多的。
- 本地域名服务器向其他服务器的迭代查询:当本地域名服务器向其他(根/权威)域名服务器进行查询时,该服务器要么返回IP地址,要么告诉本地域名服务器:”你下一步应该向哪个服务器进行查询”,再由本地服务器进行后续查询,该过程中,根/权威域名服务器不会替本地域名服务器进行后续查询,因此称为迭代查询。
DNS记录
DNS资源记录(Resource Record,RR)提供了主机名到IP地址的映射,它由域名的权威DNS服务器提供原始记录,由递归DNS服务器临时存储这些记录,受TTL限制。RR主要包含了以下字段:
- Name:主机名,即要解析的子域名,如:@(根域名)、www
- Value/RDATA/Content:记录的值,域名最终指向的目标(IP、域名、文本等)
- Type:记录类型,通常有以下类型:
- A记录:将域名解析为IPv4地址,如:xxx.com. IN A 88.77.66.55
- AAAA记录:将域名解析为IPv6地址,如:xxx.com. IN AAAA 2001:db8::1
- CNAME记录:称为规范名称记录,将一个域名别名指向另一个域名,如:www.xxx.com. IN CNAME xxx.com.
- MX记录:邮件交换记录,指定处理域名邮件的邮件服务器及其优先级,如:xxx.com. IN MX 10 mail.xxx.com.(数字越小优先级越高)
- NS记录:指定域名的权威DNS服务器,通常由域名商自动配置如:xxx.com. IN NS ns1.xxx.com.
- TXT记录:用于进行文本验证,常用于验证域名所有权、SPF反垃圾邮件等
- PTR记录:将IP地址解析为域名(反向解析),如:1.2.0.192.in-addr.arpa. IN PTR example.com.
- SOA记录:起始授权机构记录,每个DNS区域必须有且仅有一条SOA记录,包含区域的管理信息,如:区域的主DNS服务器、管理员邮箱、序列号、刷新间隔等
- SRV记录:即服务定位记录,用于指定特定服务(如 VoIP、游戏服务)的地址与端口,如:_sip._tcp.example.com. IN SRV 10 5 5060 sipserver.example.com.
- CAA记录:即证书颁发机构授权记录,指定哪些CA(证书颁发机构)可以为该域名颁发SSL/TLS证书,如:example.com. IN CAA 0 issue “letsencrypt.org”
- TTL(Time To Live):解析缓存的有效期,单位秒
- Priority:优先级,仅部分记录(MX、SRV)使用,数字越小优先级越高
- CLASS:DNS类别,用来指定网络类型/协议簇,通常极少用,因为它的值基本都是IN,代表Internet,可取值还有CH(CHAOS),用于调试、查询服务器版本
Type Name Content TTL
A xxx.com 22.33.44.55 Auto
CNAME www xxx.com Auto
DNS报文
DNS只有查询报文和回答报文,且它们有相同的报文格式:

- 首部区域有12字节,包含以下字段:
- 16bit的标识符,用于标识查询报文,该标识会被添加到回答报文中以匹配查询报文
- 标志:由多个标志位(每个标志位1bit)组成,区分查询报文0/回答报文1;是否为所查询域名的权威域名服务器(是则为1);是否希望执行递归查询(是则为1),对于回答报文如果支持递归查询则置为1。
- 4个数量有关的字段:它们分别代表后续4类数据区域出现的次数
- 问题区域(对于回答报文,该区域会填充查询报文中的问题作为回显)包含所查询的信息,包括所查询的域名、所查询的类型
- 回答区域(对于查询报文,该区域数量为0)包含一条或多条对最初请求的域名的资源记录,即包含RR的Type、Value、TTL等
- 权威区域包含其他权威服务器的记录
- 附加区域包含其他有帮助的记录,比如对于MX请求的回答报文,回答区域是邮件服务器的规范主机名,附加区域是邮件服务器A记录提供的IP地址
文件传输协议
FTP文件传输协议
FTP(File Transfer Protocol)文件传输协议:是一种基于TCP的明文传输协议,它提供任意计算机之间交互式的文件访问和传输,允许客户指定文件类型和格式,允许文件具有存取权限。很多操作系统的文件系统本身支持FTP协议,而不需要额外程序。
FTP使用客户服务器方式,传输时会建立两个并行的TCP连接:控制连接和数据连接。服务端会首先打开21作为控制连接端口等待连接。客户端会打开随机端口N,并连接服务器的21端口,随后告诉服务器自己的端口N+1以作为数据连接端口,随后服务器使用20端口与之进行文件传输。因此,对于服务器,它使用21作为控制连接端口,20作为数据连接端口,对于客户端,它自行选择控制和数据连接端口。
TFTP简单文件传输协议
TFTP(Trivial File Transfer Protocol)简单文件传输协议是基于UDP的小型明文传输协议,只支持文件传输而不支持交互,内存占用小,但需要有自己的差错改正功能,可固化于特殊的小型设备内直接使用,TFTP的特点为:
- 数据报文简单,使用简单的头部
- 每次传输512字节,最后一次不满512字节即作为文件结束标志,若最后一次传输满512字节,则额外传输一个只有头部的空白数据报文作为文件结束标志
- 支持ASCII码和二进制传输
- 数据报文按序编号,从1开始,支持读和写
SFTP基于SSH的安全文件传输协议
SFTP(SSH File Transfer Protocol)SSH文件传输协议是运行在SSH加密隧道之上的文件传输协议,它不是FTP的升级,而是一种全新的设计,支持查看、上传、下载、删除、权限修改等文件操作。传输时,客户端与服务器先建立一条SSH安全连接(依旧默认使用
远程登录协议
TELNET
TELNET(Telecommunication Network):是一种早期的远程登录协议,主要作用是让用户通过网络在远程主机上获得一个命令行终端,从而像本地操作一样执行命令。TELNET基于TCP(默认端口23)协议,建立连接后,客户端与服务器之间直接以明文形式传输数据。用户在客户端输入的字符,会被转换为NVT格式,并明文发送到服务器,服务器执行命令后,再将终端输出以同样的明文方式返回给客户端。由于其明文传输的特性,目前通常只在受控内网环境中使用。
SSH
SSH(Secure Shell):是一种安全的远程登录与远程管理协议,它不仅支持远程命令行登录,还广泛用于安全文件传输(SCP、SFTP)、端口转发等。SSH基于TCP(默认端口22),在应用层引入了一整套加密与认证机制,支持多种身份验证方式,如密码认证、公钥认证等,整个通信过程加密传输,是主流的远程管理协议。
电子邮件
一个电子邮件系统有三个主要组成部分:
- 用户代理:通常就是手机和电脑上的邮件客户端,如Gmail等,负责邮件编写、显示
- 邮件服务器:发送方和接收方都有各自独立的邮件服务器,它们既能充当客户端,也能充当服务器端。
- 邮件发送协议/邮件读取协议:邮件发送协议有SMTP,邮件接收协议有POP3,它们通常都基于TCP
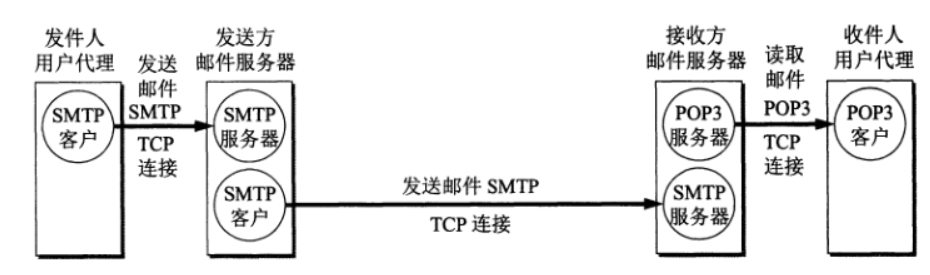
邮件系统的工作流程:
- 发件人在用户代理软件中进行邮件编写,用户代理通过SMTP协议将邮件发送到发送方邮件服务器
- 发送方邮件服务器通过SMTP协议将邮件发送到接收方邮件服务器,如果发送方邮件服务器无法与接收方服务器建立TCP连接,则邮件继续保留在发送方邮件服务器上,并在一段时间后重试,直到超过重试时间/次数,然后将结果返回给发件人用户代理
- 接收方邮件服务器接收到邮件后,存入收件人用户邮箱,等待用户代理读取,收件人通过用户代理,通过POP3(或IMAP)协议主动从接收方邮件服务器中拉取邮件
- 发送邮件是推操作,读取文件是拉操作,因此需要两个不同的协议
简单邮件传送协议SMTP
SMTP的特点
SMTP协议规定了SMTP进程之间如何交换邮件信息,诞生时间较早(1982年之前),有以下特点:
- 协议只能传输7位ASCII码,即纯英文文本,这意味着它不支持中文、阿拉伯语等非英文字符,也不支持传输图片、视频等二进制对象
- 行长度 ≤ 1000 字节
- 不支持附件
SMTP的工作流程
SMTP协议规定了14条命令和21种应答模式,命令由字母组成,应答信息由3位数字开始,后面附上简单的文本说明(也可不附,这部分文本说明是可以自定义的,程序只识别数字应答码)。SMTP的工作流程:
- 发件方用户代理将邮件发送到发送方邮件服务器,发送方SMTP服务器(SMTP客户)通过25端口与接收方SMTP服务器(SMTP服务器)建立TCP连接
- TCP连接建立后,接收方SMTP服务器发出220 文本说明应答信息,这里的文本说明RFC标准规范建议添加接收方SMTP服务器主机名,如:220 smtp.gmail.com
- SMTP客户发送HELO 发送方主机名命令并附上发送方主机名。SMTP服务器若是能接收邮件,则应答250如:250 OK,若无法接收则应答421,如:421 service not available
- SMTP客户发送MAIL FROM:发件人邮箱地址指明发件人地址,如:MAIL FROM:xxx@Gmail.com。如果SMTP服务器准备好接收,则应答250 OK,否则返回一个应答码并指出原因,如:451(处理出错),452(存储空间不足),500(命令无法识别)等
- SMTP客户发送RCPT TO:收件人邮箱地址(RCPT是recipient收件人的缩写)指定收件人地址,如果要发送给多个收件人,则发送多个RCPT命令,SMTP对每一个RCPT命令,都需要返回一个应答,如:250 OK或550 No such user here,以表示指定的邮箱是否在接收方服务器中
- SMTP客户发送DATA命令表示即将发送邮件内容,SMTP服务器应答354,如:354 Enter mail,end width “.” on a line by itself,表示邮件内容应该以独立成行的.结束。如果SMTP服务器无法接收邮件内容,则应答421(服务器不可用),500(命令无法识别)等
- SMTP客户发送邮件内容,并在邮件内容结束后发送<CRLF>.<CRLF>(即两个回车换行符之间加上.)表示邮件内容结束,SMTP服务器应答250 OK,或发生错误的应答码
- SMTP发送QUIT命令表示即将关闭SMTP连接,SMTP服务器应答221(服务关闭)并随后释放TCP连接
由于SMTP协议限制邮件的报文部首和报文体都只能使用7位ASCII码,且是明文传输,因此衍生出了ESMTP(ExtendedSMTP,扩展SMTP),它支持客户端鉴别,可以传输二进制数据,使用TLS安全传输。ESMTP在进行SMTP连接时,SMTP客户端使用EHLO命令(而不再是HELO)来确认SMTP服务器是否支持ESMTP拓展参数,并决定使用标准SMTP传输还是ESMTP传输。
邮件读取协议POP3和IMAP
POP3邮局协议是一种简约、功能有限的邮件读取协议,使用客户-服务器的工作方式,旧版本的POP3协议有一个特点:当用户从POP3服务器中读取了邮件,POP3服务器会将该邮件删除,该邮件就只存在于用户代理,当用户需要在不同设备查看邮件时很不方便,因此,后来的POP3协议进行了更新,允许用户在读取邮件后依旧保持邮件在POP3服务器中。
IMAP网际报文存取协议是一种联机协议,使用客户-服务器的工作方式,当用户运行IMAP客户程序时,会与接收方邮件服务器上的IMAP服务器程序建立TCP连接,用户可以像本地操作一样直接操作邮件服务器邮箱,用户打开邮件时,才会将邮件传输到用户本地计算机上。
MIME多用途互联网邮件扩充
传统的SMTP邮件协议只能传输纯文本的ASCII字符的局限性催生了MIME多用途互联网邮件扩展(Multipurpose Internet Mail Extensions)的发展,MIME没有推翻原有的SMTP传输方式,而是通过在邮件头中增加特定字段来描述传输的数据类型,并将二进制内容转换(如通过base64编码)为适合文本通道传输的形式,使附带多媒体的邮件仍然能够基于 SMTP 进行可靠传输。
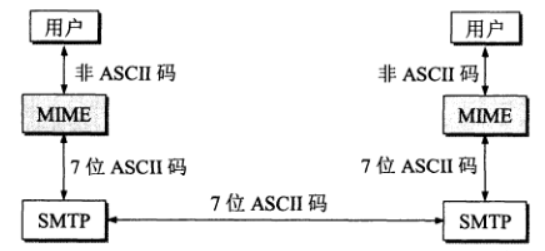
MIME定义了5个新的邮件首部字段:
- MIME-version:MIME版本
- Content-Description:对邮件主体的描述
- Content-Id:邮件唯一标识
- Content-Transfer-Encoding:邮件正文传输前采用的编码方式
- Content-Type:邮件主体的数据类型和子类型
内容传送编码
当邮件内容包含非ASCII字符,为了能通过SMTP通道传输,需要在发送前进行编码,并在接收端解码还原。MIME 规范定义了几种标准的传输编码方式,它们会在首部字段Content-Transfer-Encoding中指定:
- 7 bit:表示邮件内容本身就是标准 7-bit ASCII,不需要额外编码
- quoted-printable:主要用于以文本为主,但包含少量非ASCII字符的邮件,=号和非ASCII字节会被编码为=XX(两个十六进制数)形式,如:”系统”会被编码为=CF=B5=CD=B3
- base64:将任意二进制数据编码为由64个安全 ASCII 字符组成的文本形式,常用于附件、图片等二进制内容,但会增加约 33% 的体积。具体方法是将每24bit(3字节)数据拆分为4个6bit的单元(所以每个单元都可以使用64个字符表示A-Za-z0-9+/,=作为填充字符),不足3字节的部分使用=填充为一个字节,这样所有二进制数据都可以映射为可在文本通道中的传输的字符
- 8 bit:仅ESMTP支持,表示内容包含8-bit字节,不进行重新编码
- binary:仅ESMTP支持,表示原始二进制数据未作任何转换,要求传输链路完全支持二进制透明传输
内容类型
Content-Type用于说明邮件内容数据的类型以及解释方式,它以Content-Type:类型/子类型;参数形式表示,参数不一定添加,如:Content-Type: text/plain; charset=UTF-8。MIME类型对大小写不敏感,但是传统写法都是小写,参数值可以是大小写敏感的。
MIME类型有一些标准定义的,也允许开发者自定义,但要求自定义的类型要以字符串X-开头以避免命名冲突,以下是常用的类型和子类型
| 类型 | 说明 | 常用子类型 |
|---|---|---|
| text | 纯文本数据,包括任何人类可读文本、源代码等 | plain(纯文本,text的默认子类型)、html、xml、css、javascript |
| image | 图像或图形数据 | gif、jpeg、tiff |
| audio | 音频数据 | basic、mpeg、mp4 |
| video | 视频数据 | mpeg、mp4 |
| font | 字体数据 | woff、tff、otf |
| model | 三维物体或场景模型 | 3mf、vrml |
| application | 不属于其他类型的任何二进制数据,通常需要交给某个应用程序解释 | octet-stream(任意二进制数据,application的默认子类)、json、pdf、xml、zip |
| example | MIME类型占位符,只在文档或示例代码中使用 | example也可以用作意MIME主类的子类型示例 |
| message | 封装了多个MIME类型的消息 | http、rfc822 |
| multipart | 由多个组件组成的数据,这些组件可能各自具有不同的 MIME 类型 | mixed、alternative、parallel、digest、form-data(http中提交表单) |
DHCP动态主机配置协议
动态主机配置协议DHCP(Dynamic Host ConfigurationProtocol)用来为计算机提供即插即用连网服务,允许计算机加入新的网络和获取IP地址而不用手动操作,DHCP使用客户-服务器通信方式,基于UDP协议,工作流程为:
- DHCP服务器会在UDP67端口等待报文
- 需要IP的主机通过UDP68向所处网络广播发送发现报文(DHCPDISCOVER),目的IP地址为255.255.255.255,源IP地址为0.0.0.0
- 只有DHCP服务器才会回答此广播报文,DHCP服务器先在数据库中查找该计算机的配置信息,如果找到则返回这些信息;如果没有找到,则从服务器IP地址池中取一个地址分配。DHCP服务器的回答报文称为提供报文(DHCPOFFER),源IP地址为自身IP,目的IP地址为255.255.255.255,返回提供报文的DHCP服务器可能会有多个
- DHCP客户从多个DHCP提供报文中选择一个,并以广播形式发送DHCP Request报文(目的IP 255.255.255.255,目的MAC FF:FF:FF:FF:FF:FF),请求报文中会写入选中的DHCP服务器标识,目标服务器会进行后续应答,其他服务器会为释放为该客户端预留的IP地址
- 被选择的DHCP服务器发送确认报文DHCPACK,DHCP客户就可以使用这个IP地址了,且它会根据服务器提供的IP租用期T设置两个计时器T1和T2,它们的超时时间分别是0.5T和0.875T。当超时时间到了就要请求更新租用期。
- 当租用期过了一半(T1时间到),DHCP客户需要发送请求报文 DHCPREQUEST要求更新租用期
- DHCP服务器若同意,则发回确认报文 DHCPACK
- DHCP服务器若不同意,则发回否认报DHCPNACK,DHCP客户必须立即停止使用原来的IP地址,重新申请IP地址
- 若DHCP服务器不响应请求报文 DHCPREQUEST,则在租用期过了87.5%时(T2时间到),DHCP客户必须重新发送请求报文 DHCPREQUEST,重复上述步骤
- DHCP客户可以随时提前终止服务器所提供的租用期,只需向 DHCP服务器发送释放报文DHCPRELEASE即可
- 很多网络可能没有DHCP服务器,但每个网络至少有一个DHCP中继代理(relay agent)(通常是一台路由器),它配置了DHCP服务器的IP地址信息。当DHCP中继代理从广播中收到发现报文后,会以单播方式向DHCP服务器转发此报文,也会将DHCP的提供报文广播给需要IP的主机
套接字
如果应用无法使用现有的应用层协议(HTTP、FTP、SMTP 等),开发者就需要自行设计网络通信逻辑。此时,应用可以通过操作系统提供的系统调用和编程接口来接入互联网服务。
TCP/IP 协议的实现已经内置于操作系统的内核之中,为了让运行在用户空间的应用程序能够请求使用内核空间的网络服务,操作系统提供了一组专门的TCP/TP应用编程接口(API)。其中最为著名的是加利福尼亚大学伯克利分校为UNIX操作系统定义的API,称为套接字接口(socket interface)。
套接字现在也已经成为系统内核的一部分,开发者使用socket系统调用时,实际是操作系统把网络通信需要的存储空间、CPU时间、网络带宽等系统资源分配给应用进程,操作系统使用套接字描述符(socket descriptor,通常表示为一个整数)表示这些资源的总和,并将其返回给应用进程,一个进程可能有多个套接字,常用的套接字类型有三种:
- 流套接字(SOCK_STREAM),基于TCP
- 数据报套接字(SOCK_DGRAM),基于UDP
- 原始套接字(SOCK_RAW),允许直接访问底层协议(如 IP、ICMP等)
TCP服务的套接字
建立连接
- 创建套接字后,服务端应用程序需要通过bind系统调用绑定套接字的IP地址和端口,客户端可以不调用bind,让操作系统内核自动分配一个动态端口
- 调用listen将套接字设置为被动方式,以监听客户端的请求。UDP协议由于提供无连接服务,不使用listen系统调用。
- 调用accept来提取客户端发起的请求,UDP不使用accept
数据传输
- 客户端和服务端都使用send发送数据,使用recv接收数据。
- send需要三个变量:数据要发往的目标套接字描述符,数据要发往的目的地址,数据长度。send会把要发送的数据复制到操作系统内核的缓存中,如果缓存已满,send会被阻塞。
- recv也需要三个变量:要使用的套接字描述符,缓存地址,缓存空间长度
释放连接
客户端和服务端可以通过close来释放连接和套接字。
P2P
P2P(peer to peer,对等网络)是一种分布式网络架构,其核心思想是将网络中每个节点的地位对等化,使每个节点既充当客户端(获取资源),也充当服务器(提供资源),从而打破传统客户-服务器模式中服务器为核心的结构。
第一代P2P以Napster为代表,采用集中式目录服务器架构,主要用于MP3音乐共享(Napster也使MP3成为了网络音乐事实上的标准)。Napster的目录服务器记录用户拥有的音乐文件信息,当用户查询时,服务器返回多个下载地址,文件传输在用户间以P2P方式直接进行。这种模式下,目录服务器依然遵循传统的客户-服务器工作方式
第二代P2P以Gnutella为代表,摒弃了集中式目录服务器,采用洪泛法在用户间进行查询。为控制查询导致的通信开销,Gnutella设计了有限范围的洪泛查询,但这在一定程度上影响了查询的准确性。
第三代P2P使用分散定位和分散传输技术,尤以BitTorrent知名。
BitTorrent
BitTorrent(比特洪流)将参与同一文件分发的所有对等方集合称为洪流,并将文件的数据单元划分为固定长度的文件块(通常为256KB)。当一个新的对等方加入某个洪流后,它可以从其他对等方下载文件块,同时向其他对等方提供自己已有的文件块。当某个对等方获得完整文件后,它可以选择立即退出洪流,也可以继续留在其中为其他对等方提供文件块。
每一个洪流都有一个基础设施结点,称为追踪器,每一个对等方需要周期性地通知追踪器它仍在洪流中。当有一个新的对等方A加入洪流,追踪器会随机选择若干个(如30个)对等方并将它们的IP地址告诉对等方A,A会与它们建立TCP连接,A和所有与它建立了TCP连接的对等方称为相邻对等方。
BitTorrent使用最稀缺优先策略来决定优先传输哪些文件块,即如果A需要的某个文件块,很多相邻对方都有,则排后传输,如果该块只有少数相邻对方有,则优先传输,越稀缺的块,传输优先级越高。
当A收到多个邻居的请求时,BitTorrent采用一种基于速率评估的对换算法来决定响应哪些下载请求。A会持续监测它从邻居那接收比特的速率,并每10秒重新计算一次。A会从中选出速率最高的4个邻居,称为疏通(unchoked)对等方,只有它们能从A处获取数据块。
除上述4个疏通对象外,A每30秒会随机选择一个邻居B并向其发送数据块,如果B以足够高的速率向A回应数据,B有可能进入A的前4名列表,从而与A建立双向对换关系。这种双向对换将持续进行,直到其中一方发现速率更高的对等方为止。除上述5个对等方(4个疏通对象加1个随机试探对等方)外,A的所有其他相邻对等方均处于”阻塞”状态,无法从A处获取任何数据块,该机制能使所有对对方都能以满意的速率进行文件块传输工作。此外,BitTorrent还有残局模型、反怠慢、随机优先选择等机制保障P2P工作。